Gli algoritmi in azione in percorsi di Intelligenza Artificiale allo scopo di rilevare e contrastare la diffusione della pandemia. Tecniche innovative per alimentare e definire una conoscenza informativa per processare i dati. Una sfida dove l’uomo è sempre presente.
Perché gli algoritmi riescono a vedere quanto c’è nei dati, ma non hanno la capacità di intelligere, di capire cosa ci sia dietro ai dati. Tutto su come si dispiega il progetto C3 DTI Covid-19. Un’opportunità concreta per superare l’incertezza informativa che si è manifestata, in modo particolare, all’avvio dell’emergenza.
Nella ricerca sul Covid-19, l’incertezza informativa e la scarsità di dati medici pregressi, in particolare allo scoppio iniziale della pandemia, rappresentano notevoli sfide nell’utilizzo di metodi di Intelligenza Artificiale per rilevare e contenere la diffusione della malattia.
In questo articolo presento il progetto C3 DTI Covid-19 intrapreso dal mio gruppo di ricerca per affrontare tali ostacoli. Nella prima parte delineo brevemente in cosa consistono le tecniche di machine learning da noi utilizzate e i metodi di intelligenza aumentata con cui le incorporiamo. Nella seconda parte delineo le quattro direttive in cui il nostro progetto si dispiega e il contributo fornito dall’utilizzo di C3.ai Data Lake, per concludere infine sintetizzando le sfide e le opportunità che i nostri risultati presentano per il futuro.
Relazioni causa-effetto tra eventi
Le tecniche statistiche non sono certo nuove: essere erano già conosciute e utilizzate fin dall’antica Grecia. Oggi ci troviamo però a fronteggiare con questi stessi strumenti uno scenario notevolmente diverso. Innanzitutto, abbiamo a disposizione una quantità di dati esponenzialmente maggiore rispetto al passato, con conseguente necessità di strumenti che ci consentano di ricavare relazioni tra questi dati. Nel momento, infatti, in cui centinaia di terabytes di dati vengono generati al minuto, non è possibile per un essere umano poterli analizzare direttamente. È necessario, allora, che vengano approntati algoritmi e programmi in grado di processare i dati per individuare le informazioni rilevanti e separarle da quelle irrilevanti. In secondo luogo, in questi anni la potenza di calcolo è cresciuta a dismisura, sia come numero che come velocità dei processori. Dunque, la combinazione di questi due fattori, la disponibilità di enormi quantità di dati e l’esistenza di calcolatori sempre più veloci, ci consente di utilizzare, per estrarre informazioni, algoritmi di inferenza statistica ragionevolmente sofisticati quali quelli di machine learning, un sottoinsieme di Intelligenza Artificiale che cerca connessioni tra i dati in possesso per capire le relazioni causa-effetto tra eventi.
“Sai quello che sai, non sai quello che non sai”
Nello studio delle relazioni causative, il problema fondamentale è costituito da quelli che vengono definiti bias cognitivi: “sai quello che sai, non sai quello che non sai”. Se, ad esempio, introduco un algoritmo sulla frequenza di studenti in una classe di Ingegneria al Politecnico di Milano negli anni Settanta, l’algoritmo direbbe che la facoltà di Ingegneria è solo per uomini. Tale risultato sarebbe errato, in quanto esiste una correlazione tra i dati in analisi (la cultura dell’epoca riteneva che non fosse particolarmente appropriato per una donna studiare Ingegneria), che non costituisce però una causazione (se tu sei donna, non sei capace di studiare Ingegneria). Un risultato analogo si otterrebbe andando a porre la stessa domanda in America nel campo delle discipline scientifiche, arrivando all’erronea conclusione che le donne non siano adatte per questa materia di studio.
In realtà, questo è un problema di bias nei dati: i dati del passato ci dicono che c’è una correlazione, ma concluderne una causazione sarebbe errato. Difatti, se a essere considerate fossero le facoltà di Matematica e Fisica in Italia, si potrebbe osservare come il 65-70% degli studenti sia composto da donne, andando quindi a sfatare la conclusione americana che non siano in grado di studiare le discipline scientifiche – che dipende unicamente dai dati selezionati. Come superare questo ostacolo?
Metodi di insieme in machine learning
Nello studio di malattie nuove che possono degenerare in pandemie, utilizziamo ensemble methods, i metodi di insieme – usiamo, cioè, algoritmi diversi con parametri e architetture diverse, le cui conclusioni confrontiamo. Queste tecniche ci possono segnalare se c’è effettivamente una malattia “nuova”: infatti, se i risultati si presentano tutti con conclusioni diverse, possiamo inferire che si è in presenza di un fenomeno nuovo, non incontrato in passato e non presente nelle informazioni fornite.
Se utilizzassimo qui i metodi più comuni di Intelligenza Artificiale senza i metodi di insieme, rischieremmo di arrivare a una conclusione sbagliata. Nel caso dei malati di CovidD, per esempio, le tecniche di machine learning potrebbero dedurre che si tratti semplicemente di una polmonite in quanto “alcuni” sintomi sono comuni, mentre in realtà il Covid-19 si distingue da una polmonite classica perché non ne possiede i sintomi ma ne esibisce di nuovi che non si riescono a spiegare.
Intelligenza aumentata
Come ho già detto sopra, il machine learning ricava informazioni dai dati che gli vengono forniti, ed è a questo cui si fa riferimento quando si parla di bias: gli algoritmi possono vedere quanto c’è nei dati che vengono loro presentati, ma non hanno la capacità di intelligere, di capire se ci siano informazioni mancanti oppure limitate. Noi come esseri umani mettiamo insieme l’esperienza, l’umanità, l’intelligenza, conversazioni con altre persone, e tutta una serie di fattori aggiuntivi che ci permettono di interpretare la realtà in modo più completo. In questo senso, gli esseri umani usano ensemble methods in cui i methods sono altamente eterogenei e spesso indipendenti ma complementari.
Le nostre limitazioni derivano dalla finitezza della nostra memoria e delle nostre capacità di analisi esaustive. La combinazione della capacità di elaborazione e di immagazzinamento dei dati e della nostra intelligenza ci porta al concetto di intelligenza aumentata: la tecnologia viene utilizzata per potenziare e complementare, ma non sostituire completamente, le capacità cognitive umane.
Un esempio di intelligenza aumentata è la combinazione di un medico e di algoritmi di analisi statistica che consentono al dottore di venire aggiornato su tutte le pubblicazioni relative a uno specifico argomento rilevante per arrivare a una diagnosi – cosa che sarebbe impossibile a un essere umano, dato il numero elevatissimo di pubblicazioni esistenti su qualsiasi argomento di medicina o ingegneria, anche solo nel proprio settore. Gli algoritmi, dotati di opportuni parametri, possono “leggere” le pubblicazioni, elaborarne sintesi e proporre quali valga la pena di guardare e approfondire, sulla base del numero di citazioni, presenza di spiegazioni, diagrammi, prove e altro. Al medico vengono dunque fornite tutte le informazioni necessarie per poter arrivare a una diagnosi maggiormente informata o per richiedere ulteriori informazioni agli algoritmi di analisi.
I temi di come rendere più robusti gli algoritmi di machine learning e dell’intelligenza aumentata sono diventato prioritari, negli ultimi anni, per la DARPA – l’agenzia del Dipartimento della Difesa degli Stati Uniti incaricata dello sviluppo di nuove tecnologie che siano rilevanti alla difesa e responsabile in buona parte del progresso tecnologico dell’industria americana, dallo sviluppo di Internet e dei metodi per la progettazione di circuiti integrati, all’idea di creare una vettura a guida autonoma.
Nel nostro progetto, l’approccio fondamentale che noi seguiamo nell’utilizzo di algoritmi di machine learning per diagnosticare una nuova malattia non appena si verifica viene affiancato dall’uomo che è coinvolto nel processo. I nostri algoritmi ci permettono di elaborare i dati e presentarli in modo opportuno a un esperto, che ci si aspetta possa trovare la modalità per prendere le opportune misure per controllarne la diffusione.
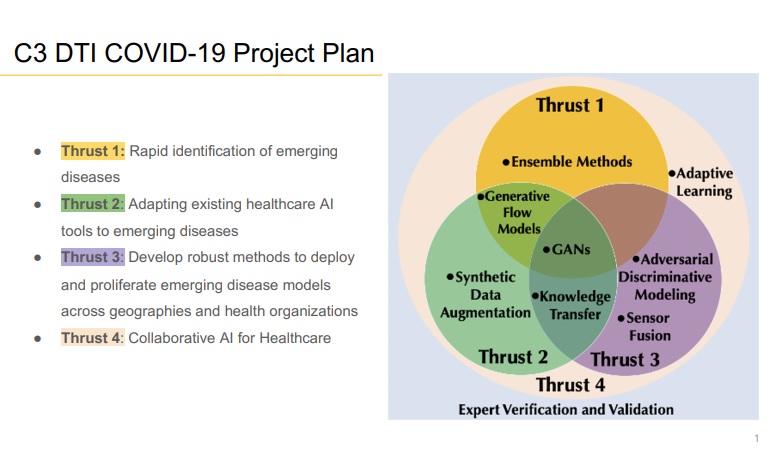
C3 DTI Covid-19 Project
Il nostro progetto C3 DTI Covid-19 si dispiega lungo quattro direttive.
1. In primo luogo, l’utilizzo di metodi di insieme in machine learning nella fase iniziale in cui arriva una malattia nuova, non appena il personale medico inizia a capire di essere di fronte a qualcosa di nuovo che non si conosce, prima che incominci a proliferare. Abbiamo proposto questi algoritmi perché in passato ci hanno fornito buoni risultati per capire la probabilità che un impianto di condizionamento si possa rompere nell’immediato futuro, a partire dall’osservazione di un rumore inusuale non incontrato prima. Il metodo applicato per gli impianti di condizionamento è analogo a quello nel caso delle malattie nuove: si tratta di riuscire a identificare quelli che chiamiamo incipient faults, problemi incipienti che non sono ancora arrivati a causare la rottura dell’equipaggiamento, ma segnalano un malfunzionamento imminente, che può essere allora evitato provando ad agire con un’operazione preventiva.
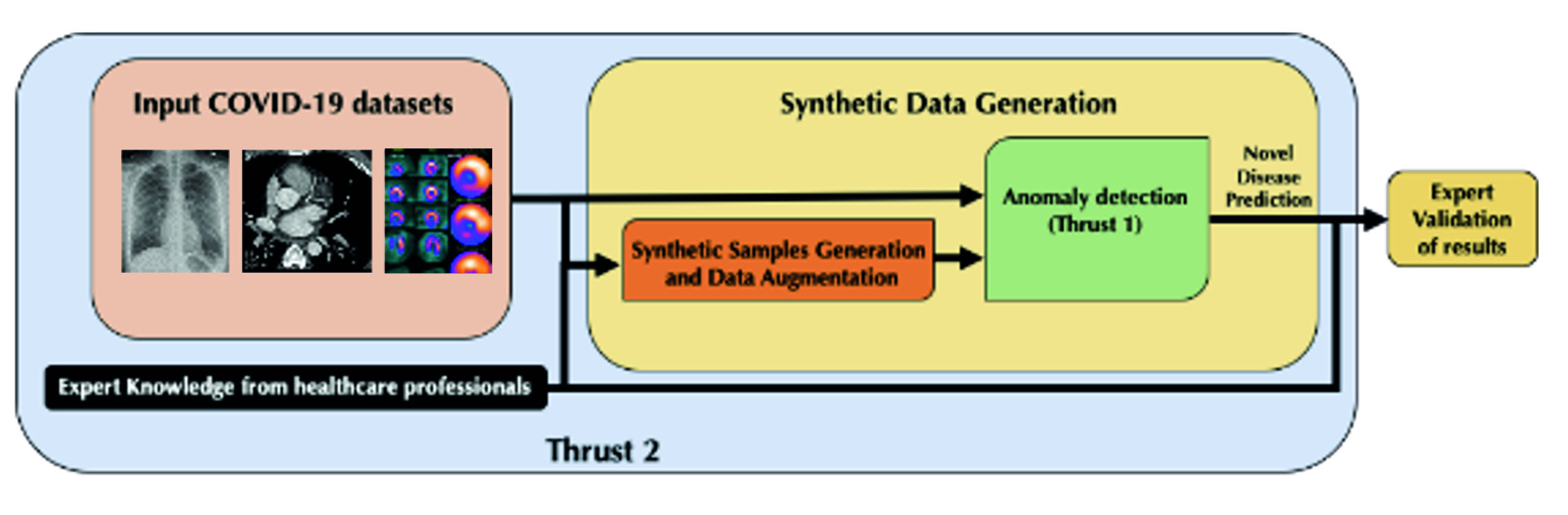
2. Un secondo aspetto della nostra ricerca affronta il problema dell’insufficienza di dati pregressi in situazioni di novità. Come è possibile, in questo caso, fare un training degli algoritmi? Un modo per risolvere il problema è di creare dei dati “artificiali” cercando delle similitudini in domini adiacenti. Ad esempio, per ottenere dati su cui fare il training degli algoritmi per diagnosticare il Covid, si ottengono dati fittizi ottenuti trasferendo dati da malattie simili come polmonite e SARS-1. Questo approccio va sotto il nome di transfering, che prende le conoscenze di un settore e le trasporta in un altro settore contiguo: benché non si possano usare esattamente le stesse, si auspica che sia possibile adattarle a quel contesto così sopperendo alla mancanza di dati.
3. Il terzo aspetto della nostra ricerca riguarda lo sviluppo di tecniche robuste per proliferare e facilitare la applicazione di nuovi modelli della malattia in diverse geografie e ospedali. La proliferazione e la applicazione dei modelli AI sviluppati devono affrontare il problema della polarizzazione delle predizioni basate su questi modelli. Per esempio, effetti spettro sono usati per descrivere lo scenario comune in pandemie dove dati per una nuova malattia quale il Covid 19 sono spesso insufficientemente quantificati a causa di conoscenze ancora limitate per caratterizzare completamente la distribuzione e la prevalenza della malattia. In questo caso, è assai importante stimare i rischi associati con la mancanza di informazioni.
4. Un quarto aspetto della nostra ricerca riguarda l’utilizzo di approcci di collaborative AI che sfruttano esperienze raccolte da medici e personale ospedaliero in aree diverse e spesso molto distanti tra di loro sia come cultura sia come possibilità di effettuare test su molti pazienti. È importante sottolineare che molti si aspettano che il futuro della AI si basi su una forte interazione tra l’uomo e la macchina. La pandemia ha sottolineato la necessità per i medici di collaborare strettamente in remoto. Il nostro scopo in questa parte della ricerca è di rendere possibile la disseminazione veloce della fisiologia, biologia e epidemiologia associate al Covid-19 provenienti da aree che sono state colpite per prime (per esempio, Cina e Italia o Seattle negli Stati Uniti) per aiutare lo sviluppo di modelli AI per regioni che saranno colpite in un secondo momento.
C3.ai Data Lake
L’utilizzo di questa tipologia di algoritmi nello studio delle caratteristiche dei malati Covid può fornire indicazioni significative anche rispetto alla predisposizione dei soggetti
al contagio o allo sviluppo di forme gravi della malattia, per esempio se si riuscisse a individuare un tratto distintivo nel sangue. Il dato statistico così ottenuto (ad esempio, “gli uomini si ammalano di più che le donne”) non è però il risultato conclusivo, ma costituisce lo spunto per tentare di capire quali sono le cause di quel comportamento, cercando di evitare il rischio, accennato all’inizio, di confondere correlazione e causazione. Potrebbe essere effettivamente il caso che in Italia ci sia una percentuale molto più alta di infetti tra gli uomini, ma è necessario allora provare a indagarne le ragioni, così come se in un’altra nazione le percentuali fossero ribaltate, occorrerebbe interpretare la causa di tali differenze. Per poter investigare in maniera efficace le relazioni di causazione, si rende allora necessario avere accesso a dati da tutto il mondo, opportunamente “tradotti” nello stesso formato e quindi confrontabili. Questo è reso possibile dall’utilizzo di un data lake, letteralmente “lago dei dati,” in cui confluiscono, come affluenti, le informazioni raccolte con metodi e strumenti informatici talora molto differenti. La funzione del data lake è quella di riversare tutti questi dati nel “lago,” e rappresentarli attraverso “traduttori di formati” in un modo uniforme, così che siano tutti organizzati allo stesso modo. Un data lake è tanto più utile quanto più è facile interrogarlo – ad esempio, effettuando una query che utilizzi come chiave la razza: “Quante diagnosi Covid avete su persone di colore?”, “Quante diagnosi Covid avete su persone bianche?”, “Quante diagnosi Covid avete su persone di origine asiatica?” Se i dati sono organizzati in maniera uniforme, è molto semplice interrogare i dati e ricevere risposte circa queste informazioni. Analogamente, per gli algoritmi l’accesso a una enorme quantità di dati è indispensabile per ottenere diagnosi accurate come risultato dell’elaborazione. Anche in questo caso, maggiore è l’uniformità dei dati e la semplicità dell’interfaccia, e più rapidamente funziona l’algoritmo. A questo scopo, nel nostro progetto utilizziamo il C3.ai Data Lake, che raccoglie i dati relativi al Covid-19 da tutto il mondo, li riversa in un formato uniforme e li rende accessibili attraverso l’utilizzo di un API, acronimo di Application Programming Interface (in italiano traducibile come Interfaccia di programmazione di un’applicazione), uno strumento di interfaccia con i dati. Se il nostro algoritmo utilizza quel particolare API offerto da C3.ai Data Lake, la nostra applicazione può quindi effettuare rapidamente qualsiasi interrogazione dei dati ed estrarne le informazioni ricercate. Sfide ed opportunità future Le evidenze teoriche che emergono dal progetto C3 DTI Covid-19 indicano che l’utilizzo di questi metodi può effettivamente aiutarci a scoprire la presenza di nuovi virus e pandemie all’inizio della loro manifestazione. Questo non garantisce che i nostri algoritmi
possano essere in grado di individuare qualsiasi nuova pandemia, perché se un nuovo virus presentasse caratteristiche per la quasi totalità uguali a virus e malattie già note (per esempio, la polmonite), i nuovi tratti distintivi potrebbero rimanere nascosti e quindi difficilmente individuabili. Tuttavia, la sfida per noi è proprio quella di continuare a perfezionare gli strumenti fino a trovare un modo per scoprire il più rapidamente possibile questi outliers che sono al di fuori della normale distribuzione di malattie note, così da poter attivare misure preventive in tempi sempre più brevi.















